The Lazy Solution!
While transferring large files from an SFTP server to Amazon S3, I faced a recurring issue: the program would frequently hang or crash while downloading the file to a temporary folder. This was especially problematic when the file size exceeded a certain limit, and the system couldn’t handle loading the entire content into memory at once.
After trying a few approaches, I landed on a solution that involved lazy reading — a technique that allowed me to stream large files in smaller chunks rather than loading them all at once.
Initial Approach: Naive File Download
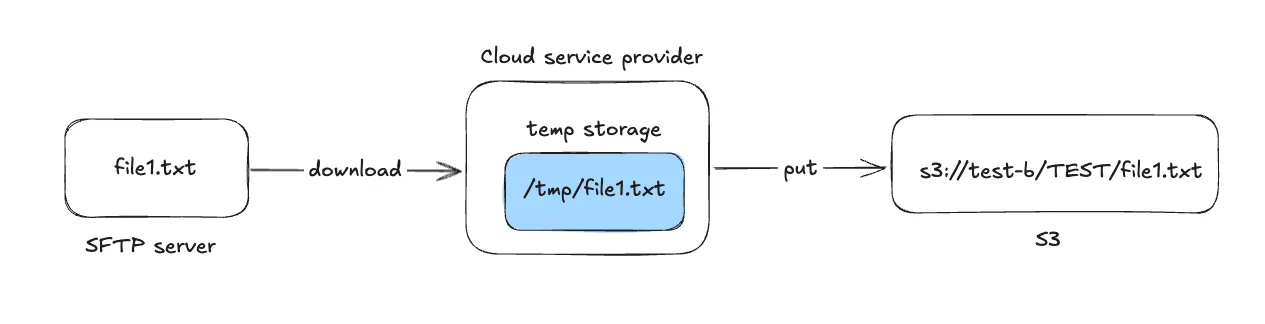
However, this failed when the file size was large — the program would freeze after about 20MB. Clearly, reading the full file at once was not scalable.
DOWNLOAD_PATH = '/tmp'
def download_files_from_sftp(records): if len(records) == 0: return [] print(records) downloaded_files = [] sftp = get_sftp_connection() try: local_path = os.path.join(DOWNLOAD_PATH) os.makedirs(local_path, exist_ok=True) for record in records: filename = record['FILENAME'] sftp_path_file = "some_path"
print(f"Processing file: {filename}") print(f"SFTP path: {sftp_path_file}") try: sftp.stat(sftp_path_file) print(f"File exists on SFTP server: {sftp_path_file}")
local_path_file = os.path.join(local_path, filename) print(f"Downloading to: {local_path_file}") sftp.get(sftp_path_file, local_path_file) print(f"Successfully downloaded: {local_path_file}") downloaded_files.append(local_path_file) sftp.close() except FileNotFoundError: print(f"ERROR: File not found on SFTP server: {sftp_path_file}") continue except Exception as e: sftp.close() print(f"Error downloading files from SFTP: {e}") return []Approach - 2: The Lazy Solution
Lazy reading is a technique where data is read in small, manageable chunks rather than loading the entire content into memory at once. This approach is especially useful when working with large files.
To avoid memory bottlenecks, I implemented lazy reading, where the file is read and written in fixed-size chunks (e.g., 32KB). This allows the program to stay responsive and memory-efficient, even with very large files.
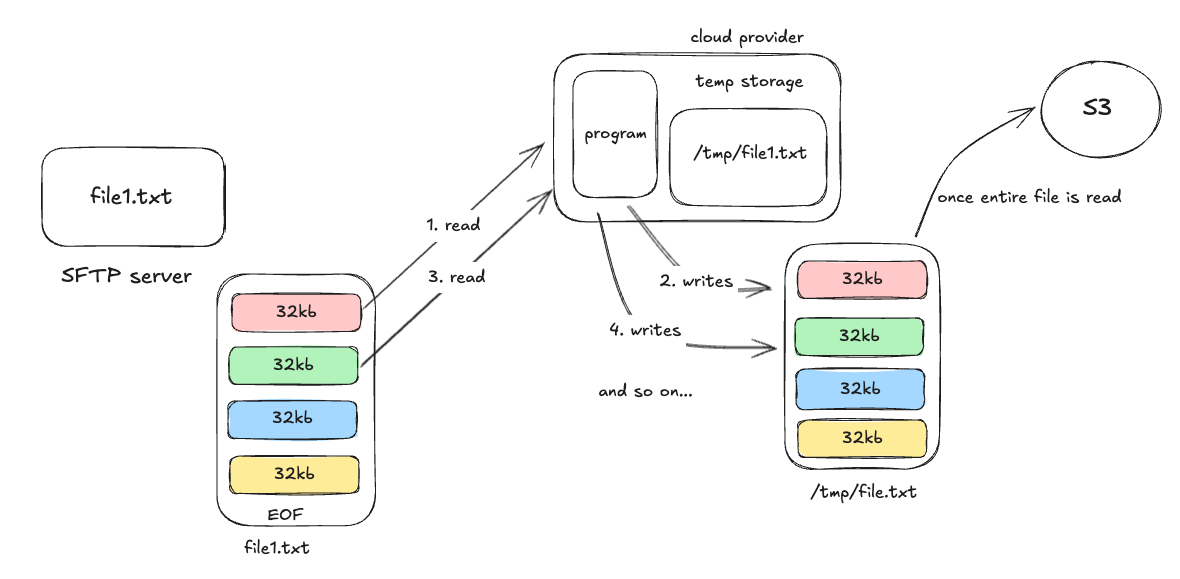
def download_large_file(sftp, remote_path, local_path): os.makedirs(os.path.dirname(local_path), exist_ok=True) with sftp.file(remote_path, 'rb') as remote_file, open(local_path, 'wb') as local_file: bytes_downloaded = 0 while True: data = remote_file.read(32768) # 32 KB chunks if not data: break local_file.write(data) bytes_downloaded += len(data) if bytes_downloaded % (5 * 1024 * 1024) < 32768: # ~every 5MB print(f"Downloaded {bytes_downloaded / (1024 * 1024):.2f} MB...")
def download_files_from_sftp(records): if not records: return []
downloaded_files = [] sftp = get_sftp_connection()
try: for record in records: sftp_path_file = "some_path" filename = record['FILENAME'] path = record["S3_PATH"]
local_dir = os.path.join(DOWNLOAD_PATH, path) local_path_file = os.path.join(local_dir, filename)
print(f"Starting download") download_large_file(sftp, sftp_path_file, local_path_file) print(f"Completed")
downloaded_files.append(local_path_file)
except Exception as e: print("Download failed with exception:") traceback.print_exc()
finally: sftp.close()
return downloaded_files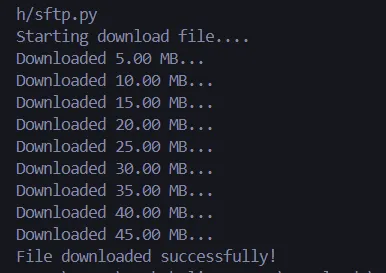
Benefits:
-
Memory Efficient: Doesn’t load the entire file into RAM.
-
Scalable: Can handle GBs of data without crashing program.
Trade-offs:
- Slightly slower due to more read/write operations.
...
Further Reading
- The Lazy Solution! 02.May.2025
- Debugging Pandas Unexpected Type Conversion 07.Feb.2025
- Part-2 More about Docker 27.Feb.2023
...